Most teams don’t struggle with “vectors.” They struggle with messy inputs: SPAs that only render in a browser, and videos that don’t ship captions. I built a single batch pipeline that ingests web and video URLs into one index, with checkpoints so production runs don’t feel like gambling.
The idea in one breath
Render real pages → chunk with structure → embed → index. For video, ask for captions first; only then pay for download + frames + vision. Everything important lands in object storage between steps, so retries are boring instead of expensive.
What the architecture is really doing
Think control plane vs data plane. Schedulers and workflow jobs decide what runs and which URL is in what state. The heavy lifting—crawling, transcoding, calling models—writes durable files so the next step doesn’t depend on memory or a single long-lived process.
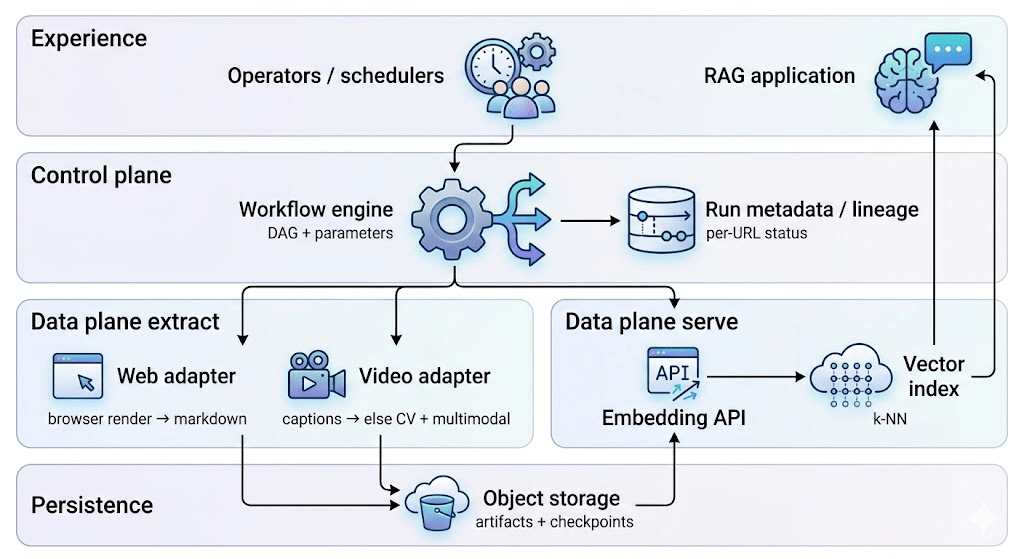
That separation is why the same pattern shows up across data and AI/ML platforms: orchestration stays thin; blobs carry truth between stages.
The batch story: checkpoints beat heroics
A healthy ingestion DAG reads like ETL with amnesia tolerance: sync the manifest, pick pending (and optionally failed) work, sanity-check the index and embedding endpoint, optionally tombstone old vectors for the same source, then extract → chunk → embed. If step three dies, you don’t automatically replay step one—not if the artifact already exists.
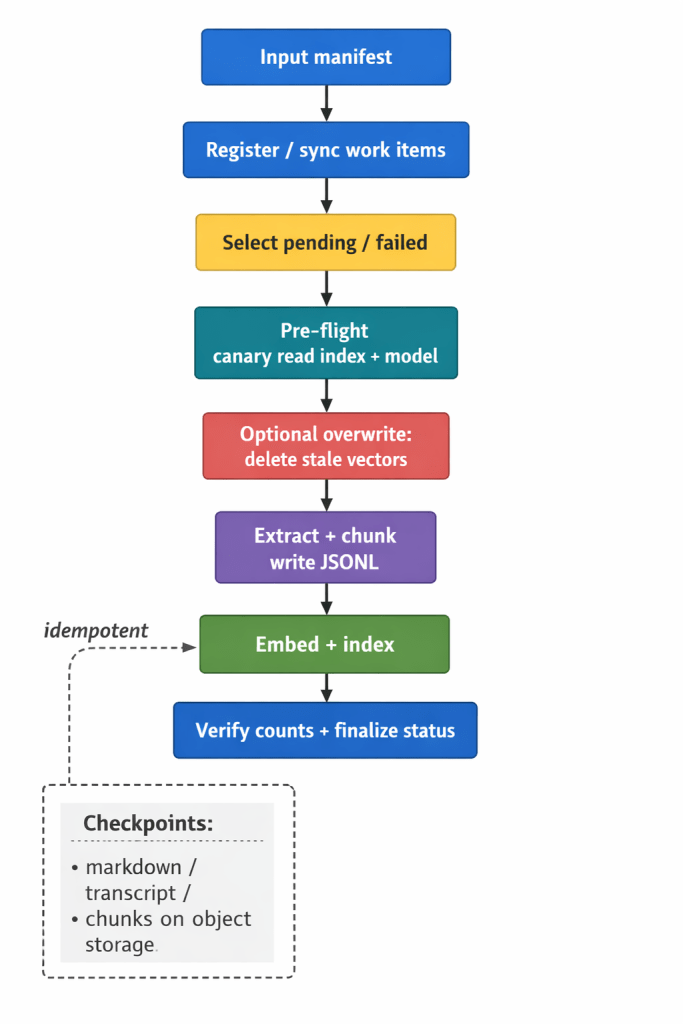
In practice, that’s the difference between “I re-crawled 10k pages because a pod restarted” and “we resumed from JSONL.”
Video: the cheap signal first
For video, the pipeline does the responsible thing: try text that already exists on the platform (captions). If that path works, you get time-bounded chunks and metadata that supports deep links into the right moment. If not, you fall back to media fetch, scene or clock-based segmentation, a bounded number of key frames, and a multimodal pass that’s tuned for facts on screen, not poetry.
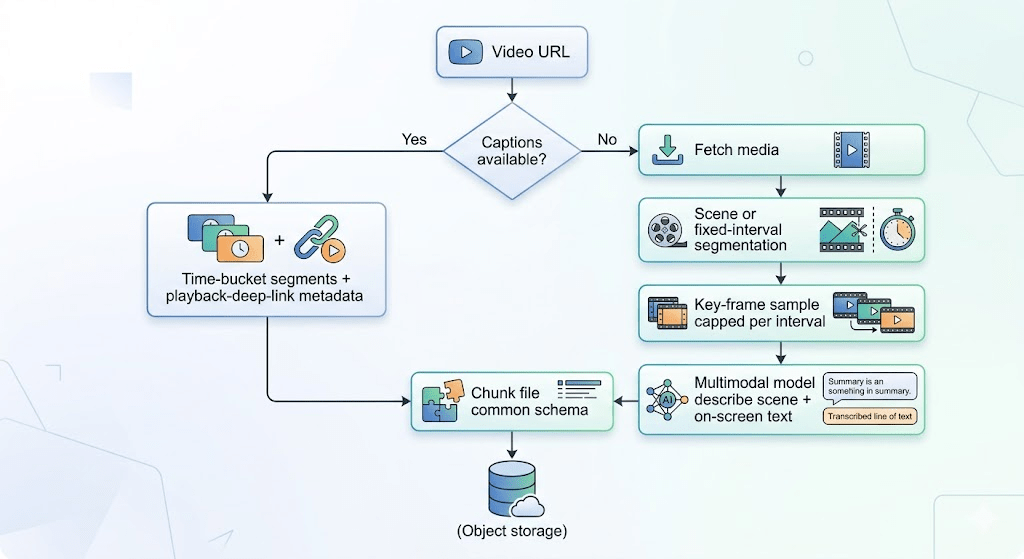
It’s the same instinct as caching and tiered inference: don’t burn GPU or tokens when plain text will do.
Making it “production-shaped” without writing a novel
You don’t need a manifesto—just a few habits that compound. Idempotent tasks that skip when outputs exist. Per-URL status so ops can retry failures without reprocessing the whole batch. Secrets outside the repo. Lazy-loading fat clients inside workers so schedulers stay light. Optional PII handling as a policy gate, not a silent default. And honest rate limits and terms-of-use hygiene for crawling and downloads—your future self (and legal) will notice.
Stack (one glance)
Typical building blocks: a workflow engine, object storage, optional key-value state for URLs, browser automation for web, chunking libraries, download + caption tooling for video, embeddings + vector DB. Swap vendors; the shape of the pipeline stays.
Closing
The useful art here isn’t “we used vectors.” It’s one schema for web and video, durable handoffs, and caption-first discipline—so retrieval stays fast to build and calm to run.

Leave a comment