Introduction
Vector-only RAG optimizes for semantic recall, but it has a predictable failure mode: relationship-heavy questions force the LLM to infer structure from unstructured text. Graph databases model that structure explicitly and support reproducible traversals, but they don’t replace semantic retrieval. This post walks through GraphFusion AI, an intent-aware hybrid retrieval solution that combines OpenSearch kNN with Neo4j graph traversal, then fuses and ranks results before LLM synthesis (FastAPI + Streamlit + LlamaIndex + Azure OpenAI).
Problem: Vector RAG Doesn’t “Understand Relationships”
Most RAG pipelines are:
Documents → parse → chunk → embed → vector store → retrieve top‑k → LLM answer. Refer my previous blog https://automationcalling.com/2026/04/23/evolving-pure-vector-rag-into-graph-aware-retrieval-a-practical-path-for-existing-pipelines/
This works well for “what is X?” or “explain Y,” because vector similarity is great at semantic recall.
But it struggles when users ask questions that require explicit structure:
- “What services depend on Service A?”
- “Which controls map to this risk and what evidence supports it?”
- “What is the path from incident → component → owner?”
- “Which entity is connected to these entities via 2 hops?”
Vector search might return relevant paragraphs, but the LLM is forced to infer relationships from text. That’s fragile.
Graphs are designed for that: nodes + edges + traversals.
So the goal becomes:
Keep vectors for semantic recall, add a graph for relational reasoning, and choose the right retrieval strategy per query.
Solution: Intent-Aware Hybrid Retrieval (GraphFusion AI)
GraphFusion AI is a POC that implements:
- Vector retrieval using OpenSearch (kNN over embeddings)
- Graph retrieval using Neo4j (relationship traversal / entity-centric lookup)
- Intent detection to route queries to:
- semantic → vector only
- relationship → graph only
- hybrid → both
- Fusion + ranking to merge contexts and reduce noise
- LLM synthesis (Azure OpenAI) to produce an answer with sources and a reasoning_type output
This is not a production system. It’s a practical reference implementation to explore the design space.
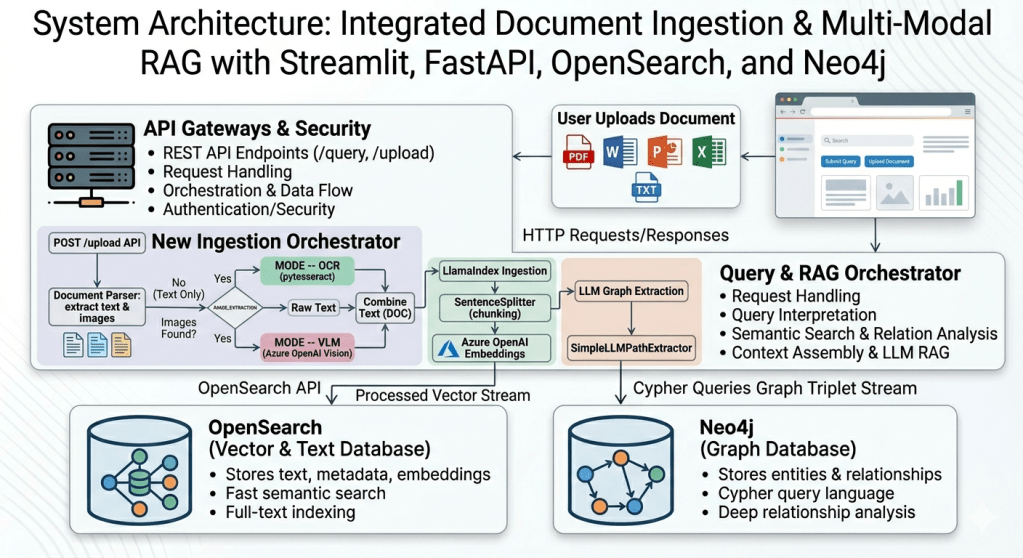
Architecture (Mental Model)
Think in two pipelines:
1) Ingestion pipeline (build the indexes)
Input: documents
Output: a vector index + a graph
Steps
- Parse documents (PDF/Word/PPT/Excel/TXT)
- Chunk text into retrievable units
- Embed chunks (Azure OpenAI embeddings)
- Index chunk vectors in OpenSearch
- Extract entities + relationships (LLM-based extraction)
- Write those entities/edges into Neo4j
Optional image/diagram extraction
- If a PDF contains images/diagrams:
- OCR mode: extract raw text
- VLM mode: use a vision-capable model to pull structured signals (entities/relations) and append into the doc text before ingestion
Why this matters: diagrams often contain the real system relationships, not the prose.
2) Query pipeline (answer questions)
Input: user query
Output: ranked evidence + LLM answer
Steps
- Intent detect: semantic vs relationship vs hybrid
- Retrieve
- semantic: OpenSearch top‑k chunks
- relationship: Neo4j traversal results / graph facts
- hybrid: both
- Fuse + rank results
- LLM generates final answer + sources +
reasoning_type
Intent Detection: The “Router” Layer
Instead of treating retrieval as one-size-fits-all, GraphFusion AI turns it into a routing decision.
A simple baseline (even rule-based) can work surprisingly well:
- Relationship intent often contains: “depends on”, “connected to”, “related to”, “upstream”, “downstream”, “path”, “ownership”, “lineage”, “caused by”, “impact”
- Semantic intent: “what is”, “explain”, “summarize”, “how to”, “overview”
- Hybrid: “explain X and how it relates to Y”
Architect note: if you have an intent confidence score, you can use it to control:
- vector k
- graph hop depth
- fusion weights
- fallback behavior
Retrieval: What Each Store Is Good At
Vector store (OpenSearch)
Best for:
- synonyms + paraphrases
- fuzzy matches
- “bring me relevant passages”
Weak for:
- multi-hop relationships
- exact structural constraints
Graph store (Neo4j)
Best for:
- “neighbors”, “paths”, “lineage”, “impact analysis”
- constraints and explicit relationships
- reproducible, inspectable reasoning via traversals
Weak for:
- semantic recall if the entity isn’t extracted/linked well
- incomplete graphs (extraction errors propagate)
Design implication: you rarely want graph-only. Hybrid gives you resilience.
Fusion + Ranking (Where Hybrid Actually Wins)
Hybrid retrieval becomes useful only if you combine results sensibly.
The POC uses a straightforward fusion:
- merge vector chunks + graph facts
- deduplicate
- apply a basic scoring/ranking
Upgrade path (recommended)
- RRF (Reciprocal Rank Fusion): robust, simple, great baseline
- LLM-as-ranker / cross-encoder reranking: higher quality, higher cost/latency
- query-dependent weighting: if intent confidence is high for relationship, graph results get more weight
Architect note: treat fusion as a standalone module. That makes it easy to iterate without touching ingestion.
Running Locally (Why This POC Is Practical)
The project uses Docker Compose to start:
- OpenSearch
- Neo4j
- FastAPI API service
- Streamlit UI
This matters because hybrid RAG needs multiple moving parts, and local reproducibility is key for learning and debugging.
What to Measure (If You Want to Make This “Real”)
A hybrid system should be justified with evaluation, not vibes.
Minimum evaluation set
- 20–50 queries split across:
- semantic-only
- relationship-only
- hybrid
- For each query:
- expected evidence (chunks / graph facts)
- expected answer traits
Metrics
- retrieval quality (e.g., recall@k on evidence)
- answer groundedness (sources cited / quote match)
- relationship correctness (path correctness, edge correctness)
- latency breakdown:
- embedding time
- OpenSearch time
- Neo4j time
- fusion time
- LLM time
Common Failure Modes (And How to Think About Them)
- Graph sparsity: extraction didn’t create enough edges
- fix: better entity resolution, schema constraints, extraction prompts, iterative refinement
- Entity linking issues: same thing appears as multiple nodes
- fix: canonicalization (IDs, hashing, fuzzy match)
- Noisy hybrid context: vector top‑k floods the prompt
- fix: tighter k, reranking, RRF, intent-weighted fusion
- Latency spikes: graph traversals too deep / broad
- fix: hop limits, degree caps, precomputed subgraphs, caching
Where This Pattern Fits
Hybrid vector + graph works well for domains with real structure:
- architecture/system design knowledge bases
- security/compliance mappings
- enterprise lineage & dependencies
- incident impact analysis
- product/component knowledge graphs
Conclusion
GraphFusion AI is a technical solution showing a clean evolution path:
Vector-only RAG → Intent routing → Add graph store → Hybrid fusion → Evaluate → Improve ranking + reliability
If you’re building RAG systems over enterprise data, hybrid retrieval is one of the highest-leverage upgrades you can make—because it reduces the amount of “guessing” the LLM has to do about relationships.
Please refer to the github repo: https://github.com/automationcalling/graphfusion_ai

Leave a comment